
Aufgrund der stark steigenden Kundenanfragen zum Thema lokale KI beschäftigen wir uns seit Längerem intensiv mit den Möglichkeiten und haben bereits erste Projekte erfolgreich umgesetzt. Viele unserer Kunden suchen nach Wegen, KI lokal zu betreiben, um die volle Datenkontrolle zu gewährleisten (KI Datenschutz & DSGVO) und Kosten zu optimieren. Dieser Beitrag teilt unsere Erkenntnisse zur verfügbaren KI-Hardware, den leistungsfähigsten Open-Weight LLMs und den praktischen Anwendungsmöglichkeiten einer On-Premise KI.
Inhaltsverzeichnis:
- 1. Der Wendepunkt: Warum lokale KI jetzt für Unternehmen relevant wird
- 2. Analyse der aktuellen KI-Infrastruktur: Hardware-Optionen
- 3. Übersicht relevanter Open-Weight-Modelle
- 4. Software & Frameworks zur Implementierung
- 5. Praktische Anwendungsszenarien und wirtschaftliche Vorteile
- 6. Tabellarische Übersichten
- 7. Handlungsempfehlungen und abschließende Hinweise
Der Wendepunkt: Warum lokale KI jetzt für Unternehmen relevant wird
Die zentrale Motivation für den Wechsel zu lokaler KI, die wir in unseren Kundenprojekten immer wieder erleben, sind zwei schlagkräftige Argumente: absolute Datenhoheit und eine drastische Kostenreduktion. Viele Unternehmen hoffen zunächst, ihre vorhandene, leistungsstarke Server-Infrastruktur nutzen zu können. Hier müssen wir oft eine wichtige Klarstellung vornehmen: Für den performanten Betrieb moderner Sprachmodelle (LLMs) sind klassische CPUs und große Mengen Arbeitsspeicher nicht der entscheidende Hebel. Der eigentliche Schlüssel zur Leistung, den wir in jedem erfolgreichen Projekt einsetzen, liegt in spezialisierter Hardware – den Graphics Processing Units (GPUs). Ihre Fähigkeit, tausende Rechenoperationen parallel auszuführen, ist die Grundvoraussetzung, um die Milliarden von Parametern eines LLMs in Echtzeit zu verarbeiten und praxistaugliche Antwortgeschwindigkeiten zu erzielen. Ohne die passende GPU bleibt die beste KI-Anwendung in der Theorie stecken.
Die folgende Übersicht zeigt eine exemplarische Hard-/Softwarearchitektur einer lokalen KI-Anwendung:
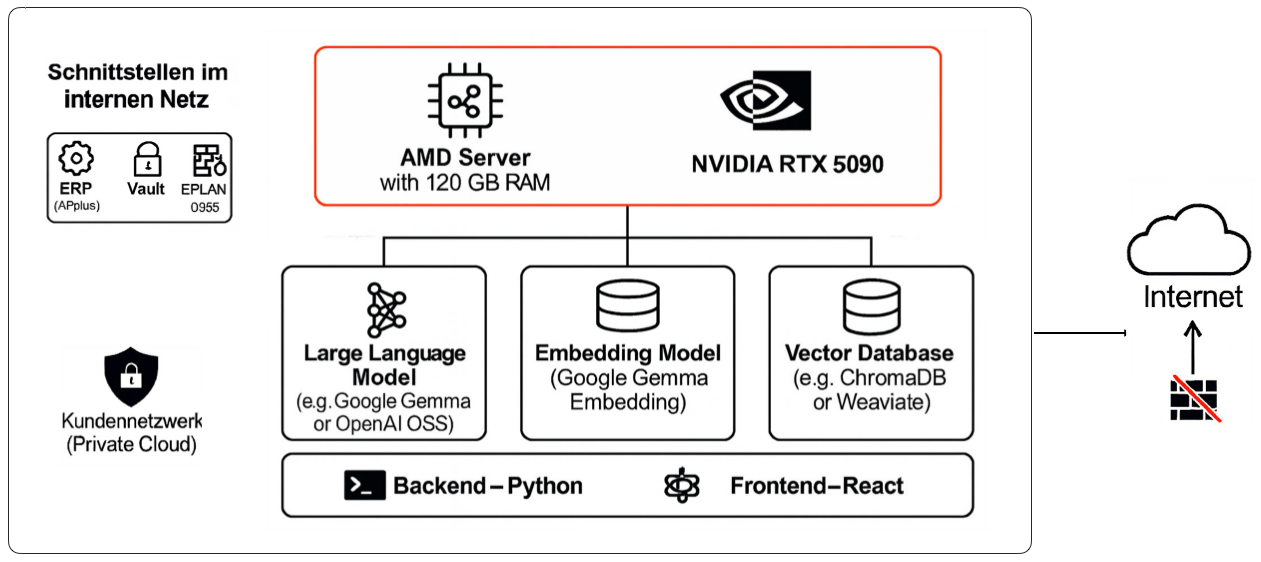
Was wir aktuell (Stand: Q3/2025) erleben, ist ein Wendepunkt, der lokale KI für ein breites Unternehmensspektrum endlich zugänglich und wirtschaftlich macht. Leistungsstarke Consumer-Hardware, hocheffiziente Open-Weight-Modelle (insbesondere mit MoE-Architekturen) und ausgereifte Inferenz-Frameworks haben eine Reife erreicht, die vor einem Jahr noch undenkbar war. Diese Kombination ermöglicht es uns, für unsere Kunden Systeme aufzusetzen, die in vielen Anwendungsfällen etablierten Cloud-Lösungen ebenbürtig sind.
Analyse der aktuellen KI-Infrastruktur: Hardware-Optionen
![]()
Nvidia
Bei der Wahl der richtigen Hardware für lokale KI führt in der Praxis aktuell kaum ein Weg an NVIDIA vorbei. Das liegt weniger an der reinen Rechenleistung der Chips sondern am Software-Ökosystem. Mit der CUDA-Plattform hat NVIDIA über Jahre einen De-facto-Standard geschaffen, auf dem nahezu alle relevanten KI-Frameworks, Bibliotheken und Modelle optimal laufen.
Gleichzeitig etabliert sich AMD als wichtiger neuer Player auf dem Feld. Ihr Software-Stack ROCm hat zwar noch nicht den Reifegrad von NVIDIAs CUDA, holt aber rasant auf und wird monatlich stabiler. Mit dem richtigen Setup lassen sich bereits heute zuverlässige Systeme für den sicheren Betrieb lokaler KI-Anwendungen realisieren, wie wir weiter unten im Detail zeigen.
Für zuverlässige und performante KI-Projekte, wie wir sie für unsere Kunden umsetzen, setzen wir aktuell trotzdem noch auf das bewährte und stabile NVIDIA-Portfolio.
NVIDIA RTX 50 Serie (2025)
RTX 5090: Die Spitzenklasse für 65B+ Modelle mit 32GB GDDR7 VRAM. Erreicht 213 tokens/sec (8B) und 61 tokens/sec (32B) (LocalLLM Performance Tests). Realpreis 2.700-3500 € (ComputerBase).
RTX 5080: Mit 16GB GDDR7 erreicht sie 132 tokens/sec (8B) und 35-40 tokens/sec (30B) (Hardware Corner Vergleich).
RTX 5070 Ti: Bietet 16GB GDDR7 für 100+ tokens/sec (8B) und 25-30 tokens/sec (30B) (TechPowerUp Specs). UVP 749$, verfügbar meist für 850-1.000€ (GamersNexus Review).
RTX 5070: Mit 12GB GDDR7 erreicht sie 100 tokens/sec (8B) und 18-22 tokens/sec (30B Q4).
NVIDIA RTX 40 Serie: Bewährte Alternativen
RTX 4090: Solide Option für 65B-Modelle mit 24GB VRAM, aber mit 1.600-1.800€ oft teuer (Puget Systems Performance).
RTX 4070 Ti Super (12GB): Erreicht 82 tokens/sec (8B) und 15-18 tokens/sec (30B) für 580-650€.
RTX 4060 Ti 16GB: Budget-Option mit 45 tokens/sec (8B) und 8-12 tokens/sec (30B) für 450-480€.
NVIDIA DGX Spark: Turnkey-Lösung für die professionelle Entwicklung
NVIDIA DGX Spark ist ein KI-Komplettsystem, basierend auf dem GB10 Grace Blackwell Superchip mit 128GB Unified Memory. Es richtet sich an Entwickler, Forscher und Studenten, die eine Plug-and-Play-Lösung suchen. (Offizielle Seite)
Fähigkeiten: Kann 200B-Parameter-Modelle lokal ausführen; zwei Systeme können für 405B-Modelle geclustert werden. (ServeTheHome Analyse)
Preis & Verfügbarkeit: Ab 3.999$ für 4TB-Konfiguration. Verfügbar ab Q2 2025 über ASUS, Dell, HP, Lenovo. (IDC Analyse)
AMD Ryzen AI MAX+ 395: CPU-basierte Inferenz & die Software-Herausforderungen
 Mit dem Ryzen AI MAX+ 395 ("Strix Halo") bietet AMD seit diesem Jahr eine leistungsstarke Alternative zu den dedizierten Grafikkarten von NVIDIA an.
Mit dem Ryzen AI MAX+ 395 ("Strix Halo") bietet AMD seit diesem Jahr eine leistungsstarke Alternative zu den dedizierten Grafikkarten von NVIDIA an.
Das entscheidende Funktionsprinzip dieser CPU ist die Unified Memory Architektur. Anders als bei Systemen mit dedizierten Grafikkarten gibt es keine physische Trennung zwischen dem Arbeitsspeicher (RAM) für die CPU und dem Grafikspeicher (VRAM) für die GPU. Stattdessen greifen alle Einheiten – CPU, GPU und NPU – auf einen gemeinsamen, bis zu 128 GB großen LPDDR5X-Speicherpool zu, der über eine breite 256-Bit-Schnittstelle angebunden ist. Dieser integrierte Ansatz ermöglicht nicht nur den effizienten Betrieb lokaler KI-Anwendungen, sondern erlaubt durch seine einzigartige Speicherarchitektur sogar den Einsatz von Modellen, die deutlich größer sind, als es auf gängigen Consumer-GPUs bisher möglich war.
In der Praxis gibt es jedoch noch viele Berichte zu Instabilitäten und auch Performance Problemen mit Backends, zudem gibt es fallweise Inkompabilitäten mit einigen LLM je nachdem welches Backend verwendet wird.
Kritische Software-Realität
Backends wie AMD VLK sind schnell aber instabil (Crash bei >2GB Buffer), ROCm leidet unter Abstürzen. Stabile Alternativen wie RADV sind langsamer. (Real-World Experience)
Komplexe Konfiguration
Erfordert manuelle Anpassungen im BIOS (512MB GPU-Speicher), spezielle Kernel-Parameter (Linux 6.15+) und empfohlene Betriebssysteme wie Fedora 42.
Dennoch kann durch die richtige Abstimmung von Betriebssystem (Fedora), Serverkonfiguration, Backend und Sprachmodell ein stabiler und performanter Betrieb auf dem Ryzen AI MAX+ 395 gewährleistet werden. Das folgende Video zeigt ein solches Setup in aller Ausführlichkeit:
Verfügbarkeit von AMD Ryzen AI MAX+ 395 Desktop-Systeme
Aktuell gibt es noch wenige Hersteller die den AMD Ryzen AI MAX+ in Ihren Systemen verbauen, zu nennen sind lediglich (Stand 09/2025):
HP Z2 Mini G1A (Professionell): 2.300-6.700€, mit 32-128GB RAM und Workstation-Zertifizierungen. (HP Official)
GMKtec EVO-X2 (Enthusiast): 1.499-2.199€, mit Triple-Fan-Kühlung, Versand aus China. (GMKtec Website)
Framework Desktop (DIY): 1.999$ für das 128GB-Kit, modularer Aufbau, verfügbar Q3 2025. (Framework Official)
Übersicht relevanter Open-Weight-Modelle
Die Hardware schafft die Grundlage, aber die eigentliche Intelligenz und Leistungsfähigkeit Ihrer lokalen KI-Anwendung steckt im Sprachmodell. Die Auswahl des richtigen Modells ist daher ein entscheidender Schritt, der direkt den Projekterfolg bestimmt. Unsere Projekterfahrung zeigt klar: Für anspruchsvolle Unternehmensaufgaben braucht es Modelle ab ca. 30 Milliarden Parametern. Erst in dieser Größenordnung erreichen sie eine Performance, die eine echte Alternative zu kommerziellen Cloud-APIs darstellt.
Um die Erwartungen richtig zu setzen: Die heutigen Top Open-Weight-Modelle konkurrieren nicht mit den allerneuesten proprietären Flaggschiffen. Sie erreichen aber souverän das Niveau der kommerziellen Spitzenmodelle von vor 8 bis 12 Monaten. Für die Praxis bedeutet das: Für die meisten Unternehmensanwendungen wie Dokumentenanalyse, Code-Assistenz oder interne RAG-Systeme ist diese Leistung nicht nur ausreichend, sondern exzellent. Im Folgenden stellen wir die Open-Weight-Modelle vor, die wir nach unseren Analysen für den Praxiseinsatz in 2025 empfehlen.
OpenAI GPT-OSS-20B: MoE-Modell (21B Parameter) für Reasoning und agentische Aufgaben. Läuft auf 16GB VRAM. (Model Card)
Qwen3-30B-A3B: MoE-Modell (30.5B Parameter), das bei hoher Geschwindigkeit GPT-4o-Niveau erreicht. Benötigt 15-20GB VRAM. (Model Card)
Google Gemma 3 27B: Hybrides Modell, stark in Coding, Mathematik und Logik. Benötigt 16-18GB VRAM. (Google AI Blog)
DeepSeek-R1-Distill-32B: Spezialisiert auf mathematisches Reasoning, benötigt 16GB VRAM. (Model Card)
Yi-34B & Mixtral 8x7B: Bewährte Alternativen. Yi-34B ist stark in EN/CN (Hugging Face), Mixtral 8x7B ist multilingual (FriendliAI Performance).
Software & Frameworks zur Implementierung
Mit der passenden Hardware und dem richtigen Sprachmodell sind die Kernkomponenten unseres Setups definiert. Für die technische Inbetriebnahme ist jedoch eine weitere Software-Schicht unerlässlich, denn ein LLM ist per se nicht lauffähig – es ist eine Ressource, die für den produktiven Einsatz erst aktiviert werden muss. Hier kommen Inferenz-Frameworks und Management-Tools ins Spiel.
Man kann sie als das Betriebssystem der lokalen KI betrachten. Sie übernehmen die kritischen Aufgaben: die effiziente Ladung des Modells in den VRAM, die Verwaltung der Hardwareressourcen und vor allem die Bereitstellung einer standardisierten Schnittstelle, meist einer OpenAI-kompatiblen API. Die Wahl des richtigen Tools hängt dabei vom Anwendungsfall und dem gewünschten Grad der Kontrolle ab.
Ollama: Etabliert sich als "Docker für LLMs" mit Ein-Kommando-Installation und exzellenter AMD-Unterstützung. (Ollama Website)
LM Studio: Bietet eine grafische Oberfläche, Headless-Modus und RAG-Funktionalität. (LM Studio Website)
Text Generation WebUI: Eine mächtige Wahl für Entwickler mit Multi-GPU-Support und LoRA-Training. (GitHub)
llama.cpp: Das technische C++-Fundament vieler Frameworks, optimiert für maximale Performance. (GitHub)
Praktische Anwendungsszenarien und wirtschaftliche Vorteile
Die Entscheidung für lokale KI ist immer dann strategisch richtig, wenn es um sensible Daten, hohe Verarbeitungsvolumina oder den Bedarf an Anpassbarkeit geht. Aus unseren Projekten haben sich vier Kernbereiche herauskristallisiert, in denen On-Premise-Lösungen ihre Stärken voll ausspielen und einen direkten wirtschaftlichen Mehrwert schaffen.
2. Intelligente Dokumentenverarbeitung (IDP)
- Was es ist: Automatisierte Extraktion, Klassifizierung und Analyse von Informationen aus unstrukturierten Dokumenten wie Rechnungen, Verträgen, Lieferscheinen oder Berichten.
- Warum Lokal? Compliance und Datenschutz sind hier die Haupttreiber. Finanzdaten, juristische Dokumente oder Personalakten unterliegen strengen Vorschriften (DSGVO, HIPAA). Eine lokale Verarbeitung stellt sicher, dass diese sensiblen Daten das Unternehmensnetzwerk niemals verlassen.
- Leistungsfähigkeit & Grenzen: Für die Extraktion strukturierter Daten (z. B. Rechnungsnummer, Datum, Betrag) sind lokale Modelle extrem leistungsfähig und zuverlässig. Sie können trainiert werden, spezifische Dokumentenlayouts zu erkennen. Bei sehr schlechter Scanqualität oder extrem seltenen, handschriftlichen Dokumenten kann die Genauigkeit sinken.
- Wirtschaftlicher Vorteil: Dies ist der Bereich mit dem vielleicht größten Hebel zur Kostenreduktion. Die Verarbeitung von hunderttausenden Dokumenten pro Monat über eine Cloud-API ist extrem teuer. Eine lokale Lösung auf eigener Hardware amortisiert sich oft schon nach wenigen Monaten und senkt die laufenden Kosten um den Faktor 10 bis 50.
3. Sichere RAG-Systeme für internes Wissensmanagement
- Was es ist: Retrieval-Augmented Generation (RAG) ermöglicht es einem LLM, Fragen präzise auf Basis einer internen, kuratierten Wissensdatenbank (z. B. Confluence, SharePoint, technische Dokumentationen) zu beantworten.
- Warum Lokal? Das gesamte Unternehmenswissen – von strategischen Dokumenten über HR-Richtlinien bis hin zu technischen Spezifikationen – ist hochvertraulich. Ein lokales RAG-System, bei dem sowohl die Vektor-Datenbank als auch das LLM On-Premise laufen, garantiert, dass keine Informationen nach außen dringen.
- Leistungsfähigkeit & Grenzen: Lokale RAG-Systeme sind exzellent darin, Halluzinationen zu vermeiden, da sie ihre Antworten strikt auf die bereitgestellten Dokumente stützen. Die Qualität der Antwort hängt direkt von der Qualität und Vollständigkeit der Wissensdatenbank ab. Das Modell kann keine Fragen zu Themen beantworten, die nicht in den Quelldokumenten enthalten sind.
- Wirtschaftlicher Vorteil: Enorme Zeitersparnis für Mitarbeiter, die nicht mehr manuell nach Informationen suchen müssen. Es schafft eine "Single Source of Truth" und demokratisiert den Zugang zu internem Wissen.
4. Kontrollierte, agentische Workflows zur Prozessautomatisierung
- Was es ist: Der Einsatz von KI-Agenten, die vordefinierte, repetitive Aufgaben ausführen. Beispiele: Eingehende Support-Tickets klassifizieren und erste Antwortentwürfe erstellen, tägliche Verkaufsberichte zusammenfassen oder Social-Media-Mentions analysieren.
- Warum Lokal? Solche Agenten benötigen oft Zugriff auf verschiedene interne Systeme (CRM, ERP, Datenbanken). Einem externen Dienst weitreichende Zugriffsrechte auf diese kritische Infrastruktur zu gewähren, stellt ein erhebliches Sicherheitsrisiko dar. Lokale Agenten agieren sicher innerhalb der Unternehmens-Firewall.
- Leistungsfähigkeit & Grenzen: Lokale Modelle eignen sich hervorragend für klar definierte, regelbasierte Aufgaben. Ihre Stärke liegt in der zuverlässigen Ausführung von Routinen. Komplexe, mehrstufige Problemlösungen, die kreatives Reasoning und Weltwissen erfordern, bleiben vorerst die Domäne der größten, proprietären Cloud-Modelle.
- Wirtschaftlicher Vorteil: Automatisierung von zeitaufwendigen Routineaufgaben, was die Mitarbeiter für wertschöpfendere Tätigkeiten freisetzt und die Prozesskosten senkt.
1. Interne Code-Assistenz und Softwareentwicklung
- Was es ist: Direkte Integration von KI-Modellen in Entwicklungsumgebungen (z. B. VS Code), um Code zu vervollständigen, zu erklären, zu debuggen oder Unit-Tests zu schreiben.
- Warum Lokal? Der entscheidende Vorteil ist der Schutz des geistigen Eigentums (IP). Kein Unternehmen möchte seinen proprietären Quellcode, der den Kern des Geschäfts ausmacht, über eine externe API an Dritte senden. Lokale Modelle laufen in einer vollständig abgeschotteten Umgebung. Zudem sorgt die geringe Latenz für eine flüssige und unterbrechungsfreie Arbeitsweise.
- Leistungsfähigkeit & Grenzen: Moderne Code-Modelle wie Gemma 3 oder DeepSeek-Coder erreichen auf 30B-Niveau eine exzellente Performance für die meisten täglichen Entwickleraufgaben. Sie können auf die gesamte Codebasis eines Projekts zugreifen und kontextbezogene, hochrelevante Vorschläge machen. Ihre Grenze liegt bei der Generierung völlig neuartiger, komplexer Algorithmen – hier sind die größten Cloud-Modelle oft noch überlegen.
- Wirtschaftlicher Vorteil: Direkte Produktivitätssteigerung der Entwicklerteams und Wegfall der monatlichen Abonnementkosten pro Entwickler für Cloud-basierte Code-Assistenten.
Tabellarische Übersichten
Hardware im Vergleich: Anwendungsfelder und Performance
Top LLM-Modelle (20-35B) im Detail
Anwendungsbereiche und Kosteneinsparungen
Handlungsempfehlungen und abschließende Hinweise
Sofortiger Einstieg 2025: Eine RTX 5070 Ti mit Modellen wie GPT-OSS-20B, Qwen3-30B-A3B oder Gemma 3 27B und der Software Ollama stellt eine äußerst leistungsfähige Konfiguration dar.
Plug-and-Play für Unternehmen: NVIDIA DGX Spark für professionelle KI-Entwicklung ohne Setup-Komplexität - 200B-Modelle out-of-the-box.
Budget-Alternative: Eine RTX 4060 Ti 16GB ist dank Modellen wie GPT-OSS-20B, die speziell für 16GB-Hardware optimiert sind, eine sehr starke Option für Einsteiger.
Bahnbrechend aber komplex: AMD Ryzen AI MAX+ 395 ist die erste Consumer-CPU für 128B+ Modelle, benötigt aber erheblichen Setup-Aufwand und Linux-Kenntnisse.
Maximale GPU-Leistung: RTX 5090 bleibt die Referenz für plug-and-play 70B+ GPU-Modelle - jedoch nur bei MSRP-Preisen wirtschaftlich sinnvoll.
Für Unternehmen: RTX 50 Serie, AMD Ryzen AI MAX+ 395 und NVIDIA DGX Spark erreichen bei intensiver Nutzung (>100k tokens/Tag) einen ROI in wenigen Wochen bis Monaten.
Wichtiger Hinweis: AMD Ryzen AI MAX+ 395 ist kein Einsteiger-System - es erfordert Linux-Expertise, Kernel-Parameter-Tuning und Backend-spezifische Optimierungen. NVIDIA DGX Spark und RTX 50 Serie bieten eine deutlich einfachere Plug-and-Play-Experience.